Sasha Rush’s Training Composer 2 workshop is a compact tour of how Cursor trains its in-house coding model. The talk is less about one clever trick and more about a full system: choosing a strong open base model, continuing pretraining on coding data, running long-horizon reinforcement learning in realistic development environments, and evaluating the result on messy internal engineering tasks.
This post turns the workshop into a readable technical summary. The main thread: Composer 2 is optimized for agentic software engineering, not just for answering coding questions.
Table of contents
Open Table of contents
What Composer 2 is trying to be
Composer 2 is Cursor’s in-house coding model for agentic software engineering. Sasha frames it around a shift in user behavior: developers are moving from asking for isolated code edits to delegating broader engineering work to agents that can plan, inspect a repository, edit files, run commands, collect lint and test results, and iterate without constant supervision.
The target is therefore not only benchmark score. Cursor wants a model that is fast, competitively priced, and useful when many agents are running at once. The talk claims Composer 2 is competitive with leading frontier coding models at release while remaining efficient enough for everyday product use.
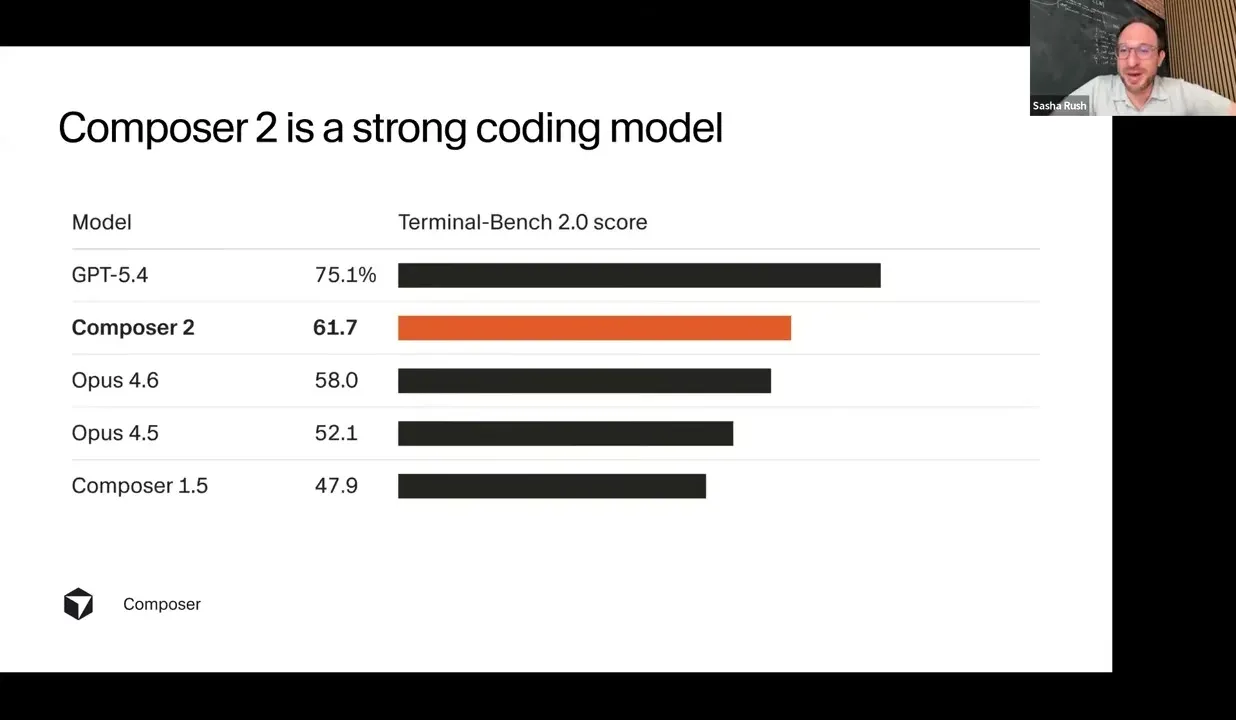
Sasha reduces the training problem to three challenges:
- Give the agent deep general coding knowledge.
- Make it run difficult tasks to completion.
- Make it work on realistic, underspecified tasks that resemble what software engineers actually ask for inside Cursor.

Deep coding knowledge comes from continued pretraining
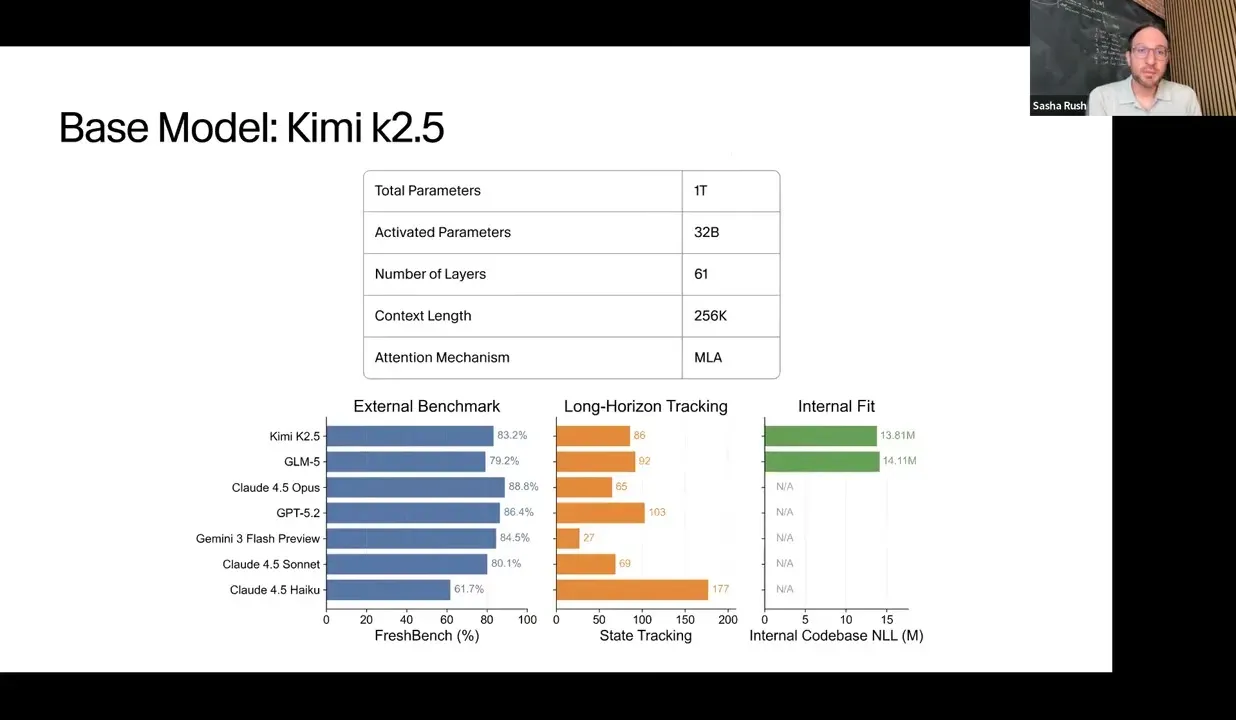
Cursor starts from a strong open base model: Kimi K2.5. The choice is partly about quality and partly about infrastructure fit. Sasha calls out its 1T total parameters, 32B active parameters, 61 layers, 256K context window, and multi-head latent attention, which helps serving efficiency.
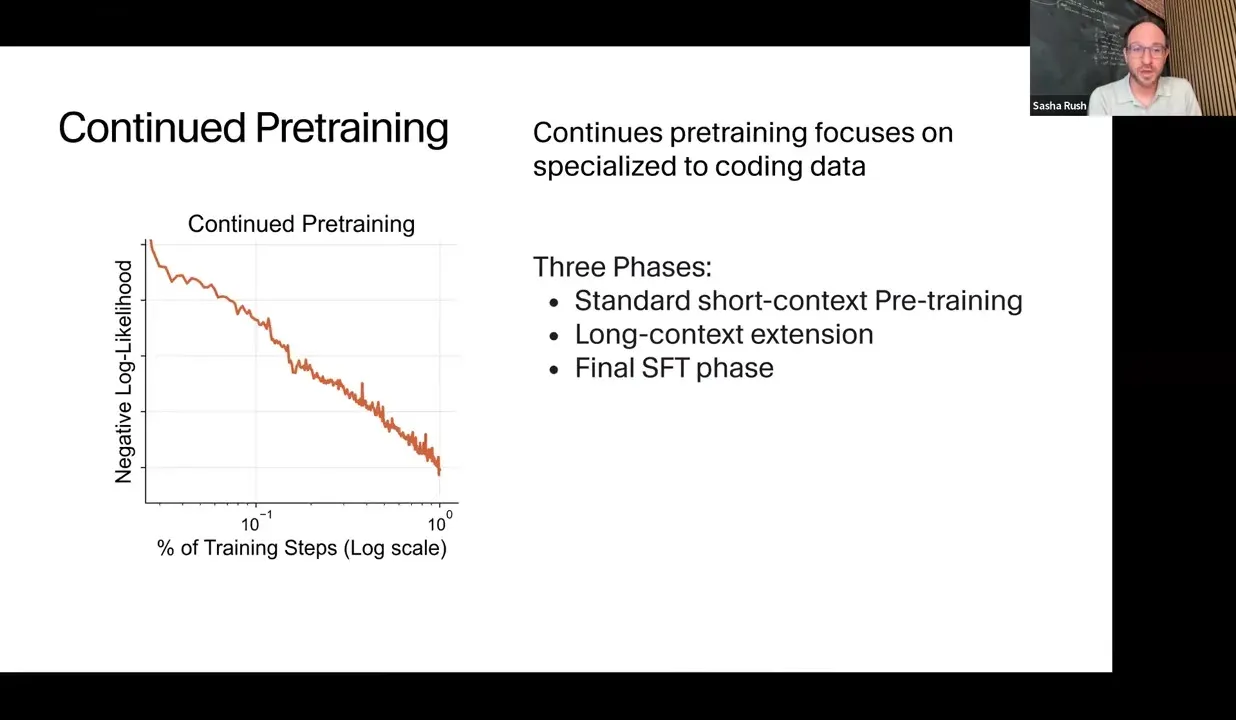
Composer 2 then receives a coding-focused continued pretraining stage. This stage is not meant to add generic chatbot knowledge. It specializes the model toward the kinds of code, repositories, workflows, and software engineering domains Cursor expects it to operate in.
The rough sequence is:
- short-context continued pretraining over many tokens;
- a long-context extension phase;
- a final supervised fine-tuning phase on more agent-like data.
Cursor validates this investment by comparing small, medium, and large pretraining variants. Lower negative log likelihood after pretraining correlates with higher reward after the later RL phase, so pretraining still matters even when the model is later optimized with reinforcement learning.
Long-horizon RL is the core training work
After pretraining, Cursor trains Composer 2 with long-horizon reinforcement learning. Sasha describes this as simulating the user queries Composer will face in Cursor as closely as possible. The goal is twofold: improve capability and tune behavior so the agent feels good to use.
Problem collection and auto-install
Cursor collects many real-world coding problems: feature iteration, debugging, new feature work, documentation changes, migrations, and project-structure management. The tasks range from easy to nearly impossible, and Sasha notes that finding tasks hard enough to keep challenging the model is itself becoming difficult.
Before RL can run, repositories need usable environments. Cursor uses an auto-install process powered by the previous Composer 1.5 model. First, the model explores the repository, reads documentation, proposes setup commands, and writes verification tests. Then Composer tries to install the environment, run checks, mock dependencies when needed, and repair failures. If verification passes, the environment becomes usable for RL training.
Rollouts are huge
For each problem, Cursor runs several rollouts. Each rollout is a simulated Cursor environment where the agent attempts the task using tools. These trajectories can reach roughly 200,000 tokens and hundreds of tool calls. Better rollouts become positive training signal; worse rollouts become signal to move away from.
A simplified way to write the objective is:
where is the agent trajectory, is task reward, and is a cost term such as completion length.

Reward shaping is about user experience
Cursor also rewards behavioral properties. A concrete example is output length. Composer should not spend excessive tokens on easy tasks, but it should be allowed to think and act longer on hard ones. Sasha says they settled on a nonlinear length penalty where the marginal penalty drops for longer reasoning, encouraging efficiency on simple work without blocking persistence on difficult work.
Conceptually:
This is not presented as Cursor’s exact internal formula; it captures the described shape: stronger pressure against needless verbosity on short tasks and lower marginal penalty on long, hard tasks.
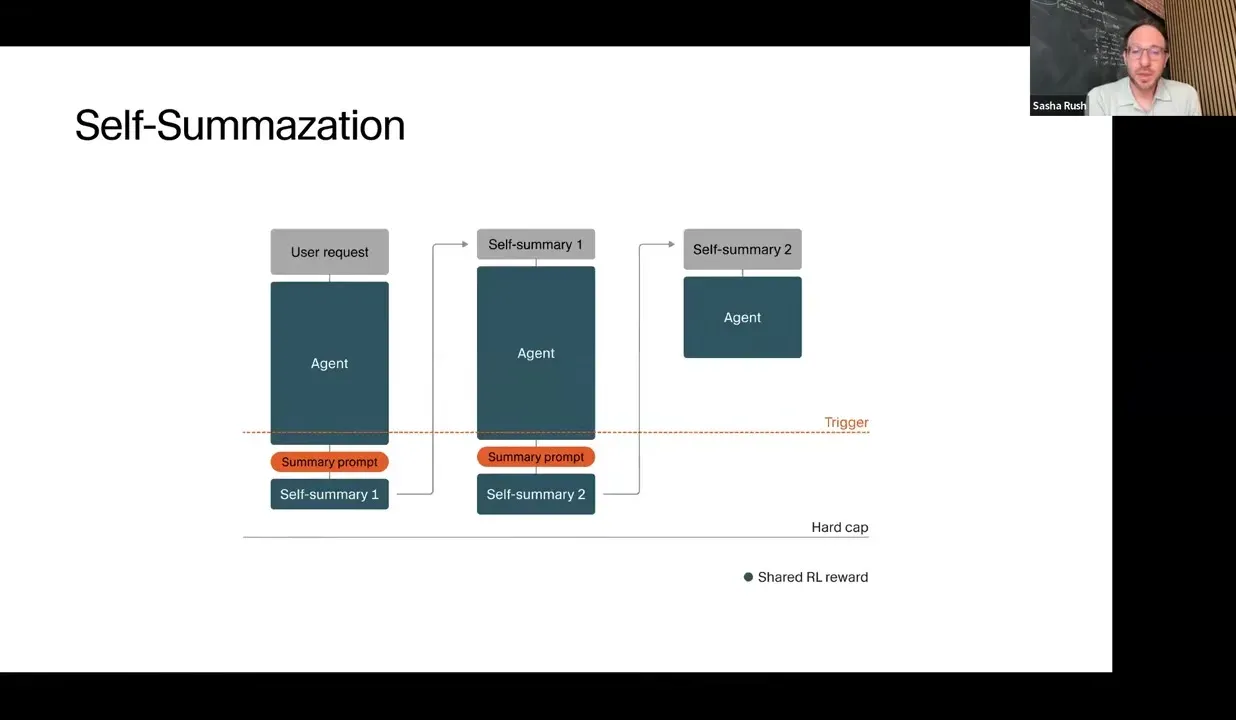
Self-summarization lets tasks run past the context limit
Self-summarization lets the model continue after a trigger point. When the agent nears a length limit, it summarizes what it has done. That summary is fed into the next segment of the same task, and RL can treat all segments as contributing to the same final reward.
This lets training encourage effectively unbounded long-horizon work while each individual segment remains bounded.
Cursor observed that training longer improved metrics continuously on a log training scale. Sasha also addresses a common RL concern: that RL might improve the best single sample while reducing diversity. In Cursor’s results, best-of-16 performance also improved, suggesting the model was not simply collapsing onto one narrow strategy.
CursorBench is built around realistic engineering work
Cursor’s evaluation strategy is deliberately internal and realistic. CursorBench is now in its third iteration and uses problems from software engineers at Cursor. The benchmark has grown longer and harder, with larger diffs and more files touched than many public benchmarks.
The benchmark goals are to remain uncontaminated, cover a range of use cases, and test more than functional correctness. The prompts are intentionally closer to real agent requests: short, messy, ambiguous instructions with incomplete capitalization, odd punctuation, references to files and logs, and sometimes external operational context such as DataDog logs.

Sasha argues that ambiguity is not a bug in the evaluation. It is part of the job. Real developers often ask underspecified questions and expect the agent to infer intent by inspecting the repository, logs, and surrounding context.

CursorBench also spreads models apart better than some public benchmarks. Sasha says many modern models score very well on SWE-bench, likely because that format has been heavily targeted for years. CursorBench shows a wider range between strong current models and older or weaker generations.
A useful diagnostic is not just score but score versus completion token length. Cursor plots models by both performance and median completion tokens because better answers often cost more tokens, and different thinking-effort modes can trade off speed, cost, and success rate.
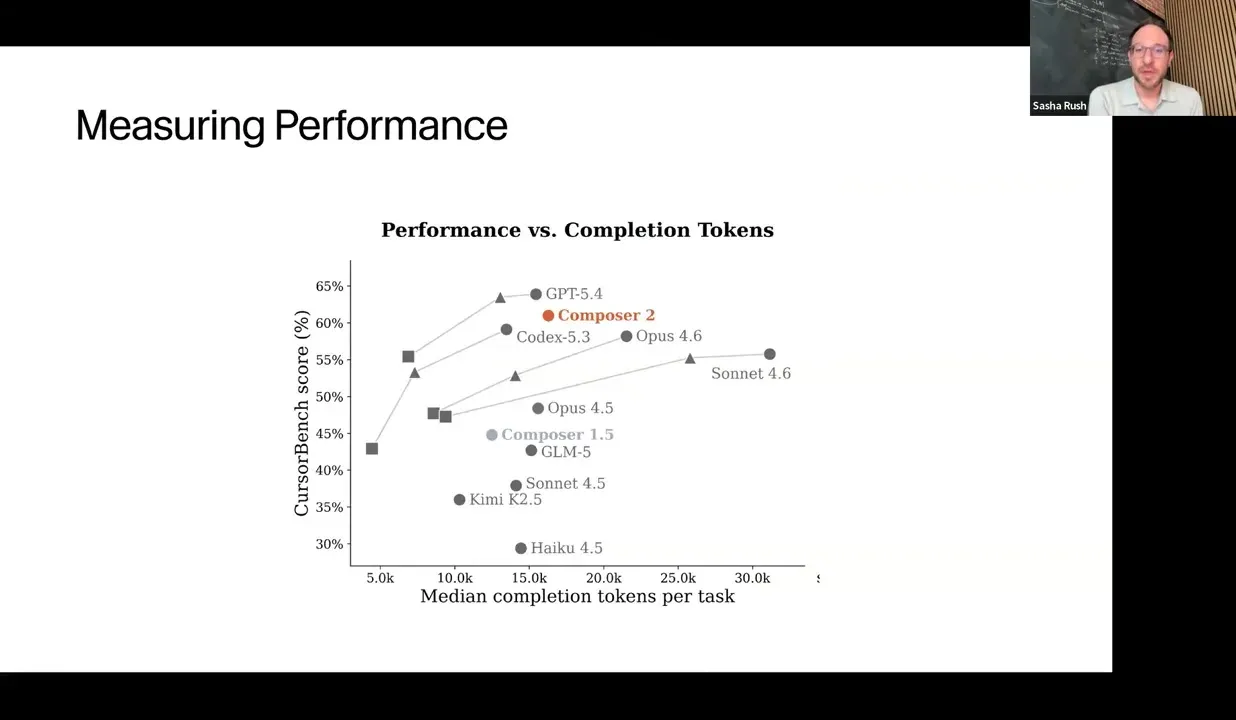
Where Cursor says the system is going
Composer 2 had already shipped by the time of the workshop, and Cursor was preparing Composer 2.5. Sasha says he hoped to discuss it directly, but it was not yet released during the talk. The preview is that Composer 2.5 should show stronger Terminal-Bench results and similar benchmark gains, driven by refinements in RL, continued pretraining, data mix, rewards, and evals rather than a completely different base system.
Cursor is also training future Composer models on a larger cluster, specifically mentioning SpaceX clusters for Composer 3 and future systems. The thesis is straightforward: coding models are already useful, but larger pretraining plus better RL should continue improving them.

Q&A notes
A few details from the Q&A are worth preserving:
- Languages and frameworks. Composer benefits from languages common in training data, especially Python and TypeScript. Swift and mobile development are harder because setup and simulation are more difficult.
- Composer 1 to Composer 2. Sasha attributes much of the jump to refining the training process: cleaner rewards, better data mix, better user-experience tradeoffs, and more effective use of compute.
- Self-summarization implementation. The same model being trained performs the summary. Cursor inserts a prompt asking the agent to summarize what happened so it can continue, then feeds that summary back into the next segment.
- Team size. About 40 people worked on Composer 2, roughly half researchers and half engineers.
- Advice for students with one GPU. Study LLM fundamentals, run small-scale RL experiments with quantized models, and learn numerics and efficiency.
- Thinking modes. Cursor has considered low/medium/high effort modes, but multiple modes add product complexity.
- Agent harness ownership. The harness is a separate product-level system used across all models, not only Composer. There is constant back-and-forth over what should be trained into the model and what should live in the harness.
- The name. Cursor originally had an agent product called Composer. As “agent” became the industry term, the product name shifted, but the team reused the old name for the model.
Takeaway
Composer 2 is best understood as a product-shaped model training system. The base model matters, but the distinctive work is in everything around it: coding-specific continued pretraining, realistic rollout environments, long-horizon RL, self-summarization, reward shaping for usable behavior, and internal evals that look like actual Cursor tasks.
The practical lesson is that coding-agent progress is no longer only about the next base model. It is about whether the training loop can reproduce the messy environment where software engineering actually happens.