Attention Mechanism
Attention Mechanism
Self Attention
KV-Cache
During inference time, the model is essentially performing next token prediction task, i.e., it is trying to generate a next token conditioned on all previously generated tokens. Take a closer look at attention, one could notice that it only needs , and in order to perform necessary calculation for the next token.
Without KV-cache, during each forward pass, the self attention block goes through calculating matrices for all previous tokens. However, there exist a huge amount of repeated calculations during the process. With KV-cache, we only use query for the last token, and append the corresponding key and value to KV-cache.
Memory usage for KV-cache is .
read more
Multi Head Attention
Multi Query Attention
In vanilla multi-head attention setting, there is a separate set of query, key and value vectors for each token. In this case, the memory usage goes up quickly for long sequence and incremental inference is often slow. Multi-query attention(MQA) instead shares keys and values across all different attention heads.
1import torch2
3B = 4 # batch4T = 128 # sequence length5D = 512 # embeddings dimension6H = 8 # number of headscc7
8D_single = D // H # single head dimension9
10torch.manual_seed(47)11X = torch.randn(B, T, D)12
13Wq = torch.nn.Linear(D, D)14Wk = torch.nn.Linear(D, D_single)15Wv = torch.nn.Linear(D, D_single)16
17Q, K, V = Wq(X), Wk(X), Wv(X)18print("Q: ", Q.shape)19print("K: ", K.shape)20print("V: ", V.shape)>>> torch.Size([4, 128, 512])>>> torch.Size([4, 128, 64])>>> torch.Size([4, 128, 64])During the calculation for block , the and vectors are broadcast to multiple heads by
Tensor.expand before doing multi-head attention.
Once the output is computed, memory for the KV-cache is free before proceeding to the next block.
1Q_ = Q.view(B, T, H, D_single).transpose(1, 2)2K_ = K.unsqueeze(1).expand(B, H, T, D_single).transpose(2, 3)3V_ = V.unsqueeze(1).expand(B, H, T, D_single)4
5print("Q: ", Q_.shape)6print("K: ", K_.shape)7print("V: ", V_.shape)The output is
>>> Q: torch.Size([4, 8, 128, 64])>>> K: torch.Size([4, 8, 64, 128])>>> V: torch.Size([4, 8, 128, 64])Grouped Query Attention
Grouped query attention is somewhat an interpolation of MHA and MQA with the goal of balancing the pros and cons. Tokens are first grouped together according to positions and share key and value vectors within groups. GQA is a balance between MHA from vanilla transformers and MQA, leveraging the advantages from both sides.
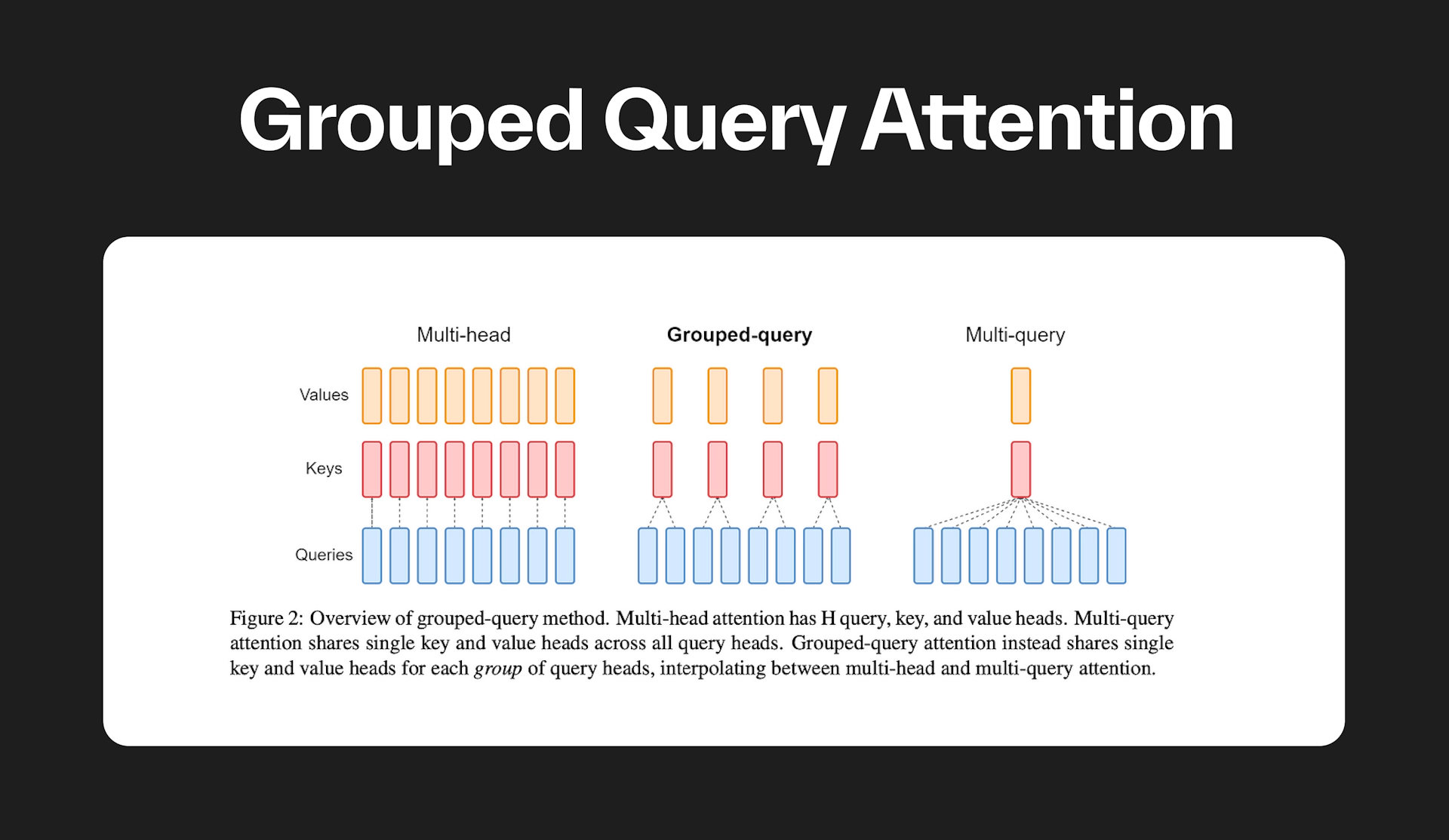
The following table is a direct comparison between dimensions of query, key, value and output for MHA and MQA. is batch size, is sequence length, is embedding dimension, is number of heads, is query/key/value vector dimension, is the number of key/value heads and is the number of groups.
Other variants of Attention
Linear Attention
read more