Generation
此内容尚不支持你的语言。
temperature
Temperature is applied by dividing by temperature right before softmax. Higher temperature leads to more
diversed output. However, do note that temperature does not change the magnitude orders of the probabilities,
hence zero impact on decoding when do_sample=False.
1class TemperatureLogitsWarper(LogitsProcessor):2 def __init__(self, temperature: float):3 if not isinstance(temperature, float) or not (temperature > 0):4 except_msg = (5 f"`temperature` (={temperature}) has to be a strictly positive float, otherwise your next token "6 "scores will be invalid."7 )8 if isinstance(temperature, float) and temperature == 0.0:9 except_msg += " If you're looking for greedy decoding strategies, set `do_sample=False`."10 raise ValueError(except_msg)11
12 self.temperature = temperature13
14 def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:15 scores_processed = scores / self.temperature16 return scores_processedtop_p
Top_p keeps the first few most probable candidates that the sum of their probabilities exceeds top_p.
The rest are masked with a filter value such as NaN so that they don’t get picked.
top_k
Top_k simply keeps the top_k most probable candidates. The rest are masked with a filter value such as NaN so that they don’t get picked.
repetition_penalty
Tokens that already occur, their probabilities got scaled down by dividing by self.penalty.
Different Decoding Strategies
greedy search
The model selects the token with the highest conditional probability in each step during generation.
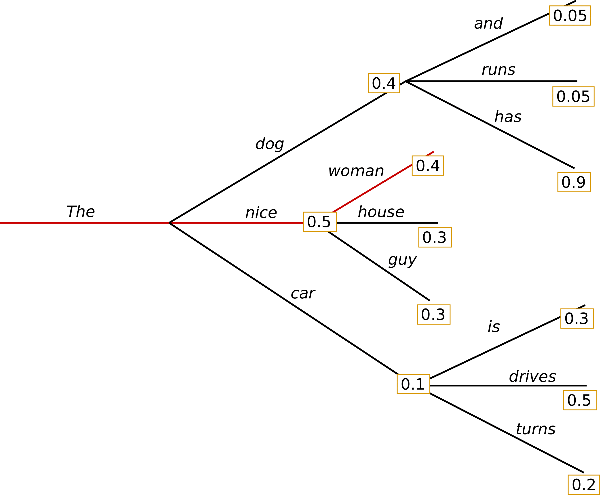
beam search
In each time step, most probable candidates are kept to the next time step where the model generates the next token for different sequences, after which the most probable sequence overall is chosen.
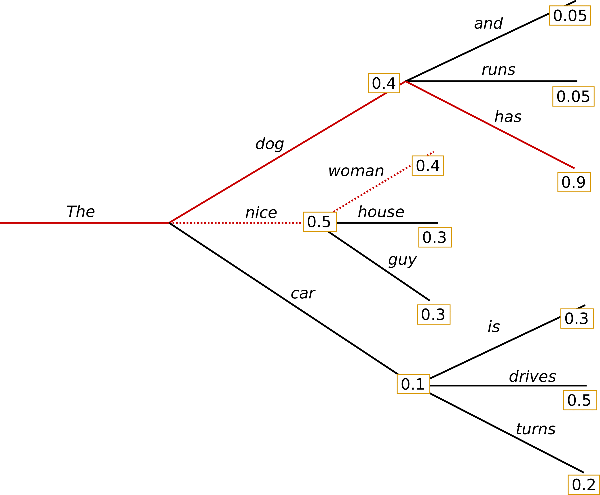
As illustrated from the graph above, in time step 1, the sequence (“The”, “dog”) and (“The”, “nice”) are reserved. In time step 2, the model generates next token for both sequences and the new sequence (“The”, “dog”, “has”) is selected because its overall probability is higher: .
constrained beam search
In open-ended generation, a couple of reasons have been brought forward why beam search might not be the best possible option:
- Beam search can work very well in tasks where the length of the desired generation is more or less predictable as in machine translation or summarization - see Murray et al. (2018) and Yang et al. (2018). But this is not the case for open-ended generation where the desired output length can vary greatly, e.g. dialog and story generation.
- We have seen that beam search heavily suffers from repetitive generation. This is especially hard to control with n-gram- or other penalties in story generation since finding a good trade-off between inhibiting repetition and repeating cycles of identical n-grams requires a lot of finetuning.
- As argued in Ari Holtzman et al. (2019), high quality human language does not follow a distribution of high probability next words. In other words, as humans, we want generated text to surprise us and not to be boring/predictable. The authors show this nicely by plotting the probability, a model would give to human text vs. what beam search does.
Quantization
An example to load a model in 4bit using NF4 quantization below with double quantization with the compute dtype bfloat16 for faster training:
1from transformers import BitsAndBytesConfig2
3nf4_config = BitsAndBytesConfig(4 load_in_4bit=True,5 bnb_4bit_quant_type="nf4",6 bnb_4bit_use_double_quant=True,7 bnb_4bit_compute_dtype=torch.bfloat168)9
10model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)sampling
stopping criteria
1from transformers import AutoTokenizer, AutoModelForCausalLM, \2 GenerationConfig, BitsAndBytesConfig, StoppingCriteria, \3 TextStreamer, pipeline4import torch5
6
7class GenerateSqlStoppingCriteria(StoppingCriteria):8
9 def __call__(self, input_ids, scores, **kwargs):10 # stops when sequence "```\n" is generated11 # Baichuan2 tokenizer12 # ``` -> 8413 # \n -> 514 return (15 len(input_ids[0]) > 116 and input_ids[0][-1] == 517 and input_ids[0][-2] == 8418 )19 def __len__(self):20 return 121
22 def __iter__(self):23 yield self24
25
26model_id = "baichuan-inc/Baichuan2-13B-chat"27tokenizer = AutoTokenizer.from_pretrained(28 model_id,29 use_fast=False,30 trust_remote_code=True,31 revision="v2.0"32)33quantization_config = BitsAndBytesConfig(34 load_in_4bit=True,35 bnb_4bit_compute_dtype=torch.bfloat16,36)37model = AutoModelForCausalLM.from_pretrained(38 model_id,39 device_map="auto",40 quantization_config=quantization_config,41 trust_remote_code=True,42)43model.generation_config = GenerationConfig.from_pretrained(model_id, revision="v2.0")44streamer = TextStreamer(tokenizer, skip_prompt=True,)45pipeline = pipeline(46 "text-generation",47 model=model,48 tokenizer=tokenizer,49 revision="v2.0",50 do_sample=False,51 num_return_sequences=1,52 eos_token_id=tokenizer.eos_token_id,53 stopping_criteria=GenerateSqlStoppingCriteria(),54 streamer=streamer,55)Speed Up Generation
speculative decoding
In speculative decoding, a small but competent draft model is used to start generating tokens. The base model(big one) is used to examine the output tokens. Tokens are accepted according to the log probabilities. The base model is then used again to actually generate tokens starting from the rejected token. It can be mathematically proved that the probability distribution is the same as if it was just the base model the whole time. Hence no performance loss while a significant speed up in generation is obtained.
Recent approaches include LLMLingua which speeds up inference by compressing prompt and KV cache with minimal performance loss, and Medusa which achieves the same performance as speculative sample by attaching and training multiple medusa heads, hence eliminating the need for small yet competent draft models. Note that Medusa indeed requires extra training.